Activation functions in Neural Network
Activation functions are a crucial component of artificial neural networks, and they play a fundamental role in determining the output of a neuron or node within the network. Imagine a neural network as a collection of interconnected nodes or neurons, organized into layers. Each neuron takes inputs, processes them, and produces an output that gets passed to the next layer or eventually becomes the final output of the network.
The purpose of an activation function is to introduce non-linearity into the network. Without activation functions, no matter how many layers you add to your neural network, the entire network would behave like a single-layer linear model. In other words, it wouldn’t be able to learn complex patterns and relationships in the data.
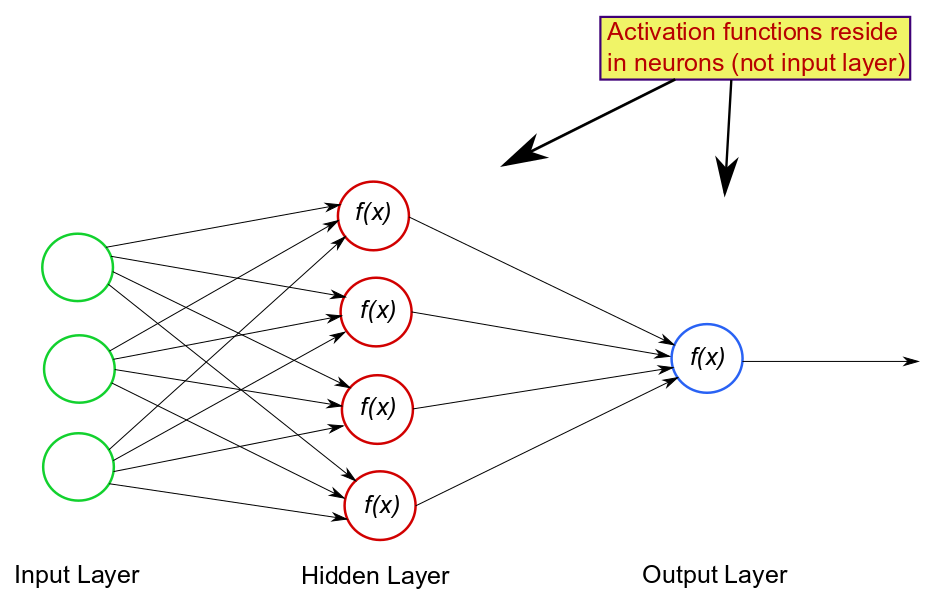
Here are some key points to understand about activation functions:
- Non-linearity: Activation functions introduce non-linearity to the neural network. This non-linearity allows the network to model and learn complex relationships in the data. Without non-linearity, the network could only learn linear transformations, which are not sufficient for solving many real-world problems.
- Thresholding: Activation functions often involve a threshold or a turning point. When the input to a neuron surpasses a certain threshold, the neuron “activates” and produces an output. This activation is what enables the network to make decisions and capture patterns in the data.
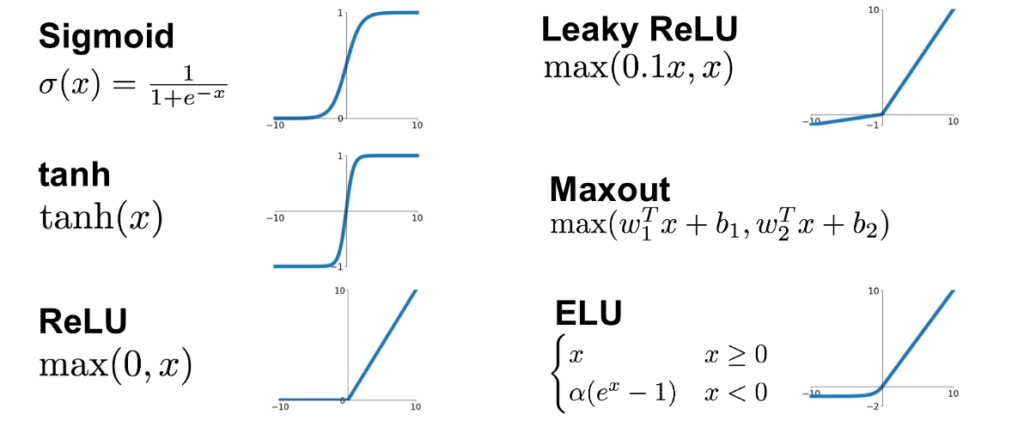
- Common Activation Functions: There are several common activation functions used in neural networks, including:
- Sigmoid Function: It produces outputs in the range (0, 1) and is historically used in the output layer for binary classification problems.
- Hyperbolic Tangent (tanh) Function: Similar to the sigmoid but produces outputs in the range (-1, 1), making it centered around zero.
- Rectified Linear Unit (ReLU): The most popular activation function, ReLU returns the input for positive values and zero for negative values. It’s computationally efficient and has been successful in many deep learning models.
- Leaky ReLU: An improved version of ReLU that addresses the “dying ReLU” problem by allowing a small, non-zero gradient for negative inputs.
- Exponential Linear Unit (ELU): Another variation of ReLU that smooths the negative values to avoid the dying ReLU problem.
- Choice of Activation Function: The choice of activation function depends on the problem you’re trying to solve and the architecture of your neural network. ReLU is often a good starting point due to its simplicity and effectiveness, but different problems may benefit from different activation functions.
- Activation Functions in Hidden Layers: Activation functions are typically applied to the output of neurons in hidden layers. The choice of activation function in the output layer depends on the type of problem (e.g., sigmoid for binary classification, softmax for multi-class classification, linear for regression).
In summary, activation functions are crucial elements in neural networks that introduce non-linearity, allowing the network to learn complex patterns and make decisions. Understanding how different activation functions work and when to use them is essential for building effective neural network models.
Question 1: What is the primary role of an activation function in a neural network?
A) To calculate the weight updates during training.
B) To introduce non-linearity into the network.
C) To determine the number of hidden layers.
D) To initialize the weights of the neurons.
Question 2: Which of the following activation functions is commonly used in the output layer for binary classification problems?
A) Sigmoid
B) ReLU
C) Tanh
D) Leaky ReLU
Question 3: What is the key benefit of using the ReLU activation function in neural networks?
A) It guarantees convergence during training.
B) It returns values in the range (-1, 1).
C) It smoothly smooths the negative values.
D) It is computationally efficient and helps mitigate the vanishing gradient problem.
Question 4: Which activation function is an improved version of ReLU designed to address the “dying ReLU” problem?
A) Sigmoid
B) Hyperbolic Tangent (tanh)
C) Leaky ReLU
D) Exponential Linear Unit (ELU)
Question 5: In a neural network, where are activation functions typically applied?
A) Only in the input layer.
B) Only in the output layer.
C) Only in the first hidden layer.
D) At the output of neurons in hidden layers.
1B – 2A – 3D – 4C – 5D