Deep Learning and Neural Networks – Let’s Dive In!
Today, we’re going to unveil the fascinating world of deep learning and how it supercharges our neural networks.
Define Deep Learning and Its Relationship to Neural Networks
Alright, picture this: neural networks are like the engines of AI, and deep learning is the fuel that makes them roar! 🚗💨
- Deep Learning: It’s a subset of machine learning where we stack multiple neural networks on top of each other. Deep learning is all about going deep (hence the name) and extracting intricate patterns from data.
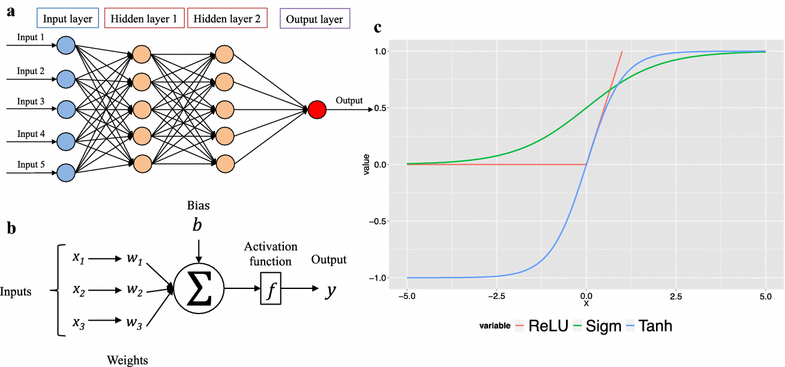
- Neural Networks: These are the brains of our AI operations. They’re designed to mimic our own brain’s structure, with layers of interconnected ‘neurons.’ Each layer processes data in its unique way, leading to more complex understanding as we go deeper.
For a deeper dive into deep learning, you can check out the official Deep Learning Guide by TensorFlow.
Learn Why Deep Neural Networks Are Powerful for Complex Tasks
Imagine your smartphone evolving from a simple calculator to a full-fledged gaming console. That’s what happens when we make neural networks deep! 📱🎮
- Powerful for Complex Tasks: Deep neural networks can tackle super tough problems. They recognize objects in images, understand human speech, and even beat world champions at board games. 🎉🏆
- Hierarchical Learning: Each layer in a deep network learns a different level of abstraction. The early layers spot basic features, like edges, while the deeper layers understand complex combinations of these features. It’s like learning to draw lines before creating masterpieces!
To see some real-world applications of deep learning, visit the Deep Learning Examples on the official PyTorch website.
Now, let’s put your newfound knowledge to the test with these questions:
Question 1: What is the relationship between deep learning and neural networks?
A) Deep learning is a type of neural network.
B) Deep learning fuels neural networks.
C) Deep learning stacks multiple neural networks.
D) Deep learning and neural networks are unrelated.
Question 2: How do deep neural networks handle complex tasks compared to shallow networks?
A) They perform worse on complex tasks.
B) They process data in a more basic way.
C) They can recognize intricate patterns and solve complex problems.
D) They require less training.
Question 3: What does each layer in a deep neural network learn as we go deeper?
A) The same information at different scales.
B) Complex patterns and combinations of features.
C) Nothing, they’re just placeholders.
D) Basic features like edges and colors.
Question 4: What’s an example of a complex task that deep neural networks excel at?
A) Simple arithmetic calculations.
B) Recognizing objects in images.
C) Identifying primary colors.
D) Writing poetry.
Question 5: What’s the primary benefit of using deep neural networks for complex tasks?
A) They require less computational power.
B) They process data faster.
C) They can understand intricate patterns.
D) They make AI less powerful.
1C – 2C – 3B – 4B – 5C